Projects
Below are some projects I have done along with a brief explanation of why and how I completed each project.
To check out the code for any of these projects, please visit my GitHub profile.
Below are some projects I have done along with a brief explanation of why and how I completed each project.
To check out the code for any of these projects, please visit my GitHub profile.
Natural Language Processing (NLP)
August 2022
Technologies Used: Python (pandas, RegEx, scikit-learn, Streamlit)
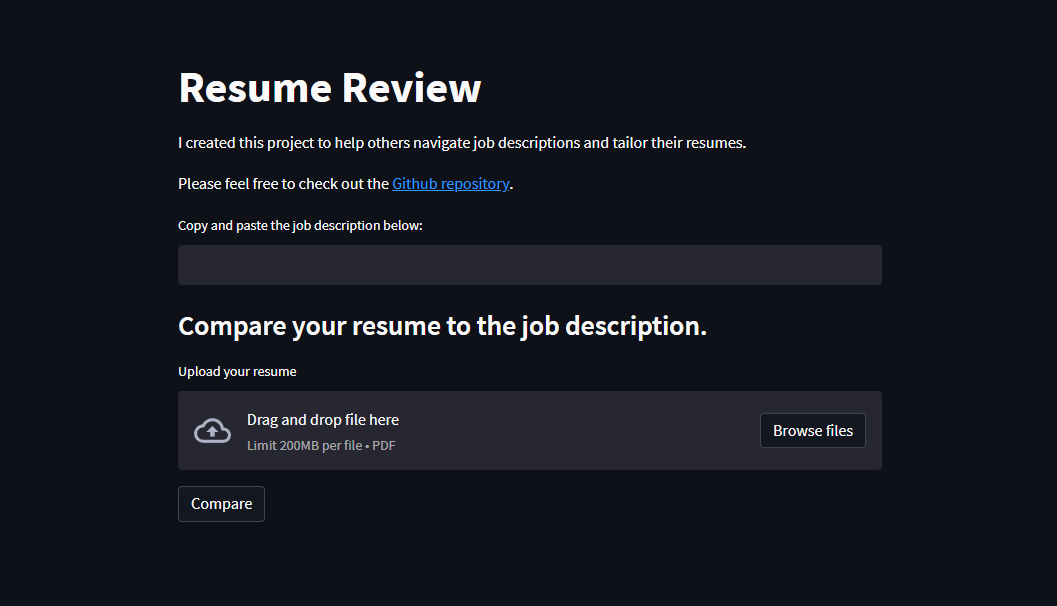
The job search process can be quite difficult and time-consuming, especially for those starting their careers or switching careers. During my search, I noticed that the “Data Analyst” role can vary from company to company. To increase the probability of receiving a callback, I tailor my resume for each application by including keywords found in the job description....
There are websites that help you acomplish this task, such as Resume Worded and Jobscan, but these are paid services. Therefore, I created this free web application to help job seekers.
This web app works by selecting the most frequent words in the job description. Then the application parses your resume to see which keywords are included. For example, if "SQL" gets mentioned numerous times, we may assume it is important, so we check if your resume contains the word "SQL".
Finally, a percentage score is generated. 0% means that no keywords are included, whereas 100% means that all the keywords are included. The user can see which keywords are included or missing and modify their resume accordingly.
Data Collection and Processing
August 2022
Technologies Used: Python (nltk, pandas, RegEx, scikit-learn, Streamlit), Twitter API
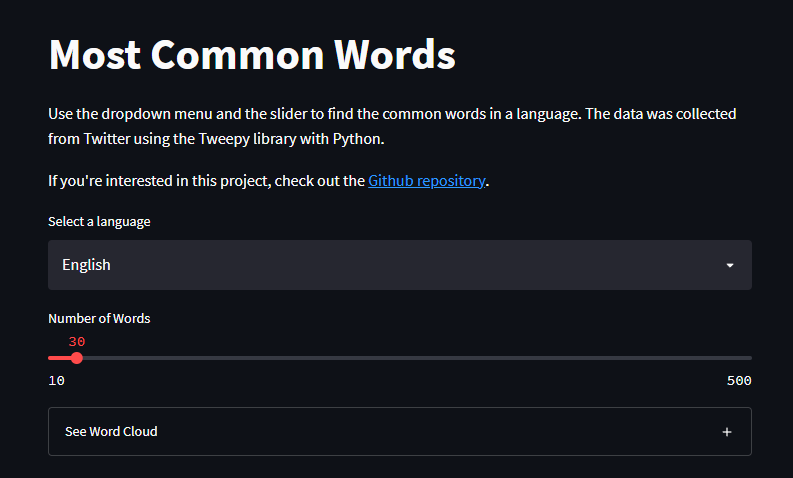
Vocabulary is very important when learning a new language. One of the most effective ways to increase one's lexicon is to study the most common words in a language. The goal of this project was to find the most common words used in tweets...
For this project, I used the Twitter API with the Tweepy library to collect 200 tweets from 10 profiles in 5 different languages. This would result in 10,000 tweets in total (in reality, this number came out lower because some of the accounts did not have 200 tweets on their profile or some tweets were only emojis).
After cleaning the data, I calculated the word frequencies and created a word cloud for each language. Using the data collected, I published a web app with Streamlit where the user can view the top x number of words in both tabular form and as a word cloud for each languages.
Data Visualization
May 2022

Technologies Used: Tableau, Python (Matplotlib, pandas)
It's helpful to know how your users navigate your application. With this information, we could improve the functionality and user experience. For this project, I analyzed data from Fitbit users to provide a recommendation for Bellabeat, a wellness company that develops fitness products for women. ...
There are two dashboards included in this project. The first dashboard shows:
The second dashboard can be found on my Tableau profile.
Data Visualization
May 2022
Technologies Used: Tableau, Python (seaborn, pandas)
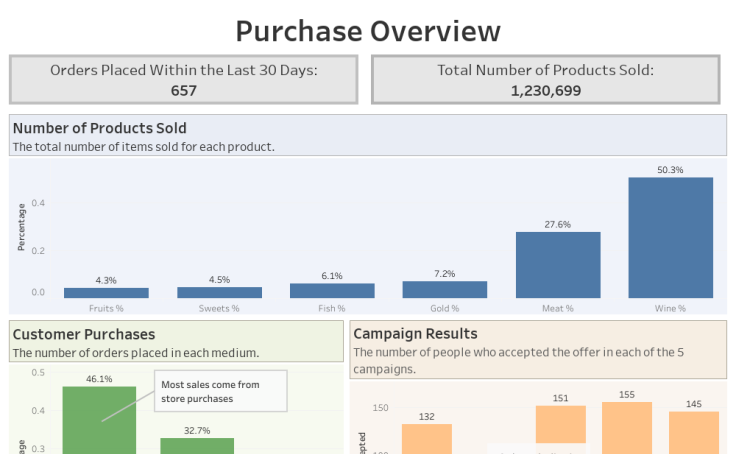
Looking at customer purchasing patterns gives us valuable information to improve our service. At a glance, this Tableau dashboard provides the most up to date information on purchases, including the number of products sold within the last 30 days, which products are selling the most, and results from past marketing campaigns....
From the dashboard, we learn that:
We also used the data to train a K Means clustering algorithm. The resulting dataset is split into three clusters.
Data Collection
April 2022

Technologies Used: Google Cloud Platform (BigQuery), SQL, Python (BeautifulSoup, NumPy, RegEx)
I visited Venice Beach in California with my family a few months ago, and while walking around I came across a bookstore called Small World Books. At the time, I had recently gotten back into reading and was excited to find a new book. That's when I noticed a collection of books that were part of the MIT Press Essential Knowledge series...
The MIT Press Essential Knowledge series is a collection of books that discusses several topics for a non-specialist audience. The topics include neuroplasticity, data science, post-truth, recycling, GPS, and many more. The beginning of every book in the series contains a short foreward, a section from this foreword reads,
“In today's era of instant gratification, we have ready access to opinions, rationalizations, and superficial descriptions. Much harder to come by is the foundational knowledge that informs a principled understanding of the world. Essential Knowledge books fill that need.”
— Bruce Tidor, MIT Professor
I highly value education and learning; I'm constantly working on learning new skills and gaining an understanding of topics I'm not very familiar with. In my opinion, every book from this series is an amazing resource to get a high-level understanding of various topics.
My goal for this project was to create a file that contains data on the books in the series. I accomplished this by web scraping text from the MIT Press public website. After finishing the project, I can now easily refer to this spreadsheet to find the next book to read.
Supervised Machine Learning
December 2021

Technologies Used: Python (nltk, NumPy, pandas, scikit-learn, Streamlit)
As an avid language learner, I enjoy listening to others speak foreign languages. Sometimes, I'll make a sorry attempt at guessing the language. So I thought it would be interesting if I could create a model that ideally could do much better...
For this project, I created a model using the Random Forest classification algorithm to predict the language of typed text. The data for this project came from the Wikipedia Language Identification Database.
The Random Forest algorithm outperformed the Naive Bayes and K Nearest Neighbors algorithms. After training the algorithm, I created a web app using Streamlit to allow users to try it out for themselves
Automation
November 2021

Technologies Used: Bash, Batch, Python (GitHub API)
Creating a new repository is not very time-consuming, but it can be a bit annoying. In my case, it can also be somewhat confusing because I manage two GitHub profiles, one is used for learning/schoolwork and the other is used for professional work and personal projects...
The steps I used to take when creating a new repository were: create the repository on GitHub with the correct account, clone the repository, configure the correct username and email, and finally open an IDE to begin working.
As previously stated, this does not take too much time, but it would be nice to have a function that would do all these steps for me, so that's what I created.
For this project, I used the GitHub API with Python to set up a repository with the correct account. Each GitHub repository is cloned into the correct folder to make it easier to manage all the projects.
Now, instead of writing multiple lines of code to set up the repo, I can just type create work new-project and everything else gets taken care of.