John Gonzalez
Data Analyst | Natural Language Processing Engineer | Data Scientist
Data Analyst | Natural Language Processing Engineer | Data Scientist
It all starts with the right data. Ensuring high quality data collection is an essential first step in any data analysis process. As the saying goes, "garbage in, garbage out."

I specialize in generating insights from datasets. Whether it be creating Tableau dashboards or analyzing data in Excel, I am ready to tackle any business problem and find a solution.
As someone who is passionate about languages and programming, natural language processing (NLP) has caught my attention. Text analytics can be useful when solving business problems.
Data science lies at the center of computer science, mathematics and statistics, and business knowledge. With the right data, many business questions can be answered with the use of machine learning algorithms
These are some of my favorite projects I've worked on!
For a complete list of my projects, you could visit the Projects page or check out my GitHub profile.
Natural Language Processing (NLP)
Technologies Used: Python (pandas, RegEx, scikit-learn, Streamlit)
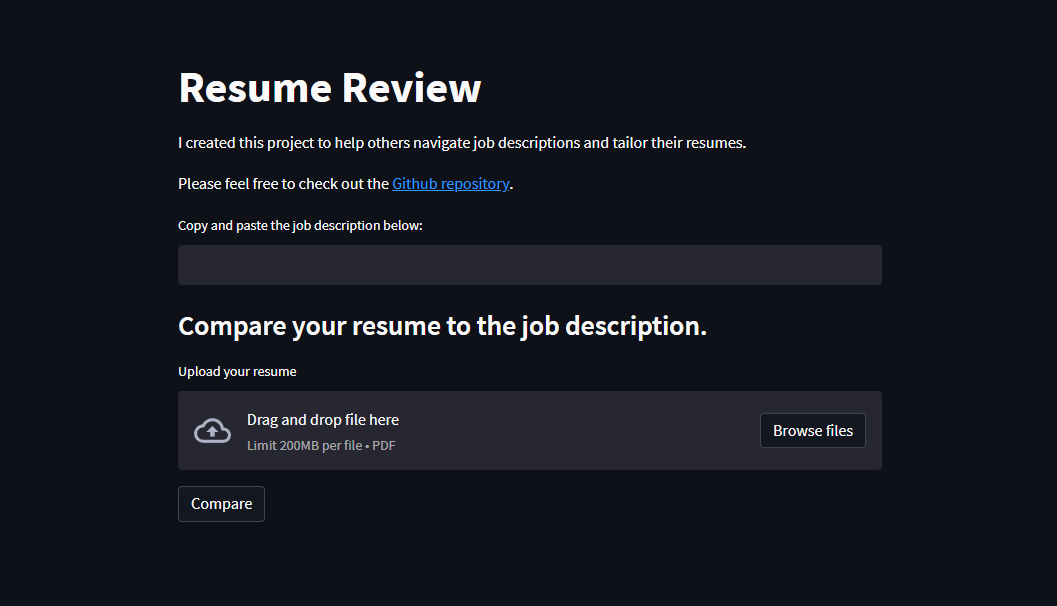
The job search process can be quite difficult and time-consuming, especially for those starting their careers or switching careers. During my search, I noticed that the “Data Analyst” role can vary from company to company. To increase the probability of receiving a callback, I tailor my resume for each application by including keywords found in the job description....
There are websites that help you acomplish this task, such as Resume Worded and Jobscan, but these are paid services. Therefore, I created this free web application to help job seekers.
This web app works by selecting the most frequent words in the job description. Then the application parses your resume to see which keywords are included. For example, if "SQL" gets mentioned numerous times, we may assume it is important, so we check if your resume contains the word "SQL".
Finally, a percentage score is generated. 0% means that no keywords are included, whereas 100% means that all the keywords are included. The user can see which keywords are included or missing and modify their resume accordingly.
Data Visualization

Technologies Used: Tableau, Python (Matplotlib, pandas)
It's helpful to know how your users navigate your application. With this information, we could improve the functionality and user experience. For this project, I analyzed data from Fitbit users to provide a recommendation for Bellabeat, a wellness company that develops fitness products for women. ...
There are two dashboards included in this project. The first dashboard shows:
The second dashboard can be found on my Tableau profile.
Supervised Machine Learning

Technologies Used: Python (nltk, NumPy, pandas, scikit-learn, Streamlit)
As an avid language learner, I enjoy listening to others speak foreign languages. Sometimes, I'll make a sorry attempt at guessing the language. So I thought it would be interesting if I could create a model that ideally could do much better...
For this project, I created a model using the Random Forest classification algorithm to predict the language of typed text. The data for this project came from the Wikipedia Language Identification Database.
The Random Forest algorithm outperformed the Naive Bayes and K Nearest Neighbors algorithms. After training the algorithm, I created a web app using Streamlit to allow users to try it out for themselves